Chatten
Im Chat sprechen Sie mit der KI in Intra AI. Sie geben eine Nachricht ein, die Antwort wird Wort für Wort zurückgestreamt, und alles, was Sie benötigen – Modellauswahl, Websuche, Dokumentenbezug und Denktiefe –, befindet sich im Eingabefeld oder direkt darüber.
Jede Konversation ist eigenständig. Das Modell und die Optionen, die Sie aktivieren, gelten für die aktuelle Konversation, nicht für alle gleichzeitig.
Auf einen Blick: Klicken Sie auf Neuer Chat in der Seitenleiste (oder beginnen Sie auf dem Startbildschirm mit dem Tippen), um eine neue Konversation zu öffnen. Alles, was Sie zur Steuerung der KI benötigen, befindet sich im Eingabefeld am unteren Bildschirmrand.
Neuen Chat beginnen#
Es gibt zwei Möglichkeiten, eine neue Konversation zu starten:
- Klicken Sie auf die Schaltfläche „Neuer Chat" oben links in der Seitenleiste. Diese öffnet immer eine leere Konversation, unabhängig davon, was Sie gerade geöffnet haben.
- Beginnen Sie auf dem Startbildschirm mit dem Tippen. Wenn keine Konversation geöffnet ist, befinden Sie sich auf dem Startbildschirm mit einem aktiven Eingabefeld. Tippen Sie einfach und drücken Sie
Enter– Ihre erste Nachricht erstellt die Konversation automatisch.
Wenn Sie einen neuen Chat öffnen, starten Sie neu: Das Modell wird auf das Standardmodell des Arbeitsbereichs zurückgesetzt, und alle aktivierten Einstellungen für Websuche, Recherche oder Denken werden zurückgesetzt.
Tipp: Wenn Sie dort weitermachen möchten, wo Sie aufgehört haben, klicken Sie auf eine vorhandene Konversation in der Seitenleiste, anstatt eine neue zu beginnen.
Modell auswählen#
Die Modell-Pille befindet sich oben in der Mitte des Bildschirms, in der Kopfzeile. Sie zeigt den Namen des aktuell ausgewählten Modells an. Klicken Sie darauf, um die Modellliste zu öffnen.
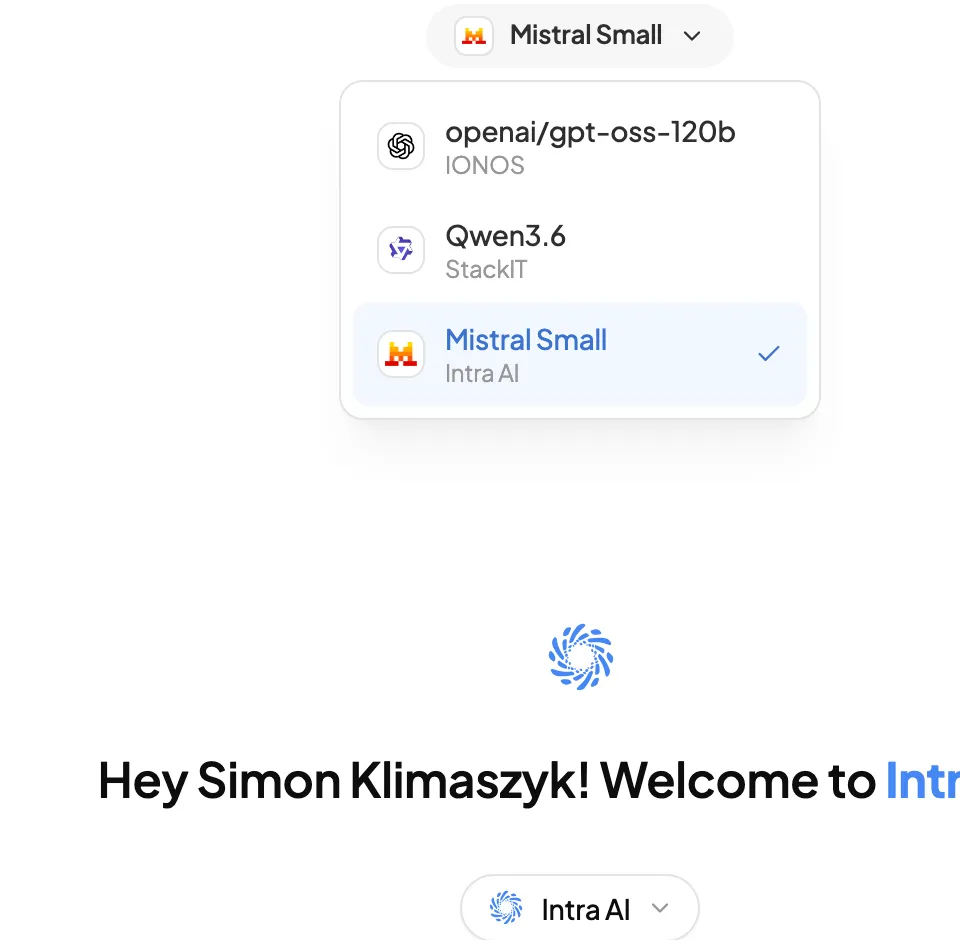 Die geöffnete Modellauswahl mit den von Ihrer Administration konfigurierten Modellen
Die geöffnete Modellauswahl mit den von Ihrer Administration konfigurierten Modellen
Ihr Administrator entscheidet, welche Modelle verfügbar sind. In einem typischen Intra AI-Arbeitsbereich könnten Sie Folgendes sehen:
| Modell | Anbieter-Bezeichnung | Hinweise |
|---|---|---|
| Mistral Small | Intra AI | Standardmodell des Arbeitsbereichs – schnell, ausgewogen |
| Qwen3.6 | StackIT | Reasoning-fähiges Modell |
| gpt-oss-120b | IONOS | Großes Open-Source-Modell |
Die genauen Namen und die Anzahl der Modelle hängen von der Konfiguration Ihres Administrators ab. Neu hinzugefügte Modelle erscheinen wenige Minuten nach ihrer Konfiguration in der Auswahl.
Sobald Sie ein Modell auswählen, bleibt es für den Rest Ihrer Sitzung aktiv. Wenn Sie die App vollständig verlassen oder die Seite neu laden, wird die Auswahl auf das Standardmodell des Arbeitsbereichs zurückgesetzt.
Hinweis: Wenn ein Agent aktiv ist, ist die Modell-Pille schreibgeschützt und zeigt ein Schloss-Symbol mit dem Namen des Agenten an. Agenten verwenden immer das Modell, für das sie erstellt wurden – innerhalb einer Agentenkonversation können Sie das Modell nicht wechseln.
Nachricht senden#
Geben Sie Ihre Nachricht in das Feld am unteren Bildschirmrand ein. Drücken Sie Enter zum Senden, oder klicken Sie auf die Senden-Schaltfläche (Pfeilsymbol rechts im Feld).
Die Antwort wird Token für Token gestreamt – das bedeutet, die Wörter erscheinen schrittweise, während die KI sie schreibt, und nicht alle auf einmal. Sie können mit dem Lesen beginnen, bevor die Antwort abgeschlossen ist.
Während das Modell schreibt, sehen Sie am Ende der Antwort einen animierten Cursor.
Stoppen, Kopieren und Wiederholen
Unter jeder abgeschlossenen (oder laufenden) Antwort erscheinen drei Bedienelemente:
| Bedienelement | Funktion |
|---|---|
| Stoppen | Hält die Antwort sofort an. Der bisher erzeugte Text wird gespeichert. |
| Kopieren | Kopiert den vollständigen Antworttext in Ihre Zwischenablage. |
| Wiederholen | Verwirft die aktuelle Antwort und fordert das Modell auf, eine neue zu erzeugen. |
Wenn Sie während einer Antwort auf Stoppen klicken, bleibt der bisherige Text erhalten – die Nachricht wird so gespeichert, wie die KI sie bis zu diesem Punkt geschrieben hat. Anschließend können Sie Wiederholen verwenden, um eine vollständige Antwort zu erhalten.
Eigene Nachrichten bearbeiten
Sie können jede von Ihnen gesendete Nachricht bearbeiten und erneut senden. Klicken Sie auf das Bearbeitungssymbol, das beim Überfahren Ihrer Nachricht erscheint, nehmen Sie Ihre Änderungen vor und bestätigen Sie. Das Bearbeiten startet die Konversation ab diesem Punkt neu: Die KI ignoriert die vorherige Antwort und reagiert stattdessen auf Ihre überarbeitete Nachricht. Das ist die sauberste Methode, einen Tippfehler zu korrigieren oder eine Frage zu verfeinern, ohne einen neuen Chat zu beginnen.
Reasoning (Denken)#
Manche Modelle können ein Problem durchdenken, bevor sie antworten – sie denken intern Schritt für Schritt und geben Ihnen dann eine durchdachte Antwort.
Die Schaltfläche Denken (Glühbirnen-Symbol) im Eingabefeld steuert dies. Klicken Sie darauf, um das Denken-Popover zu öffnen.
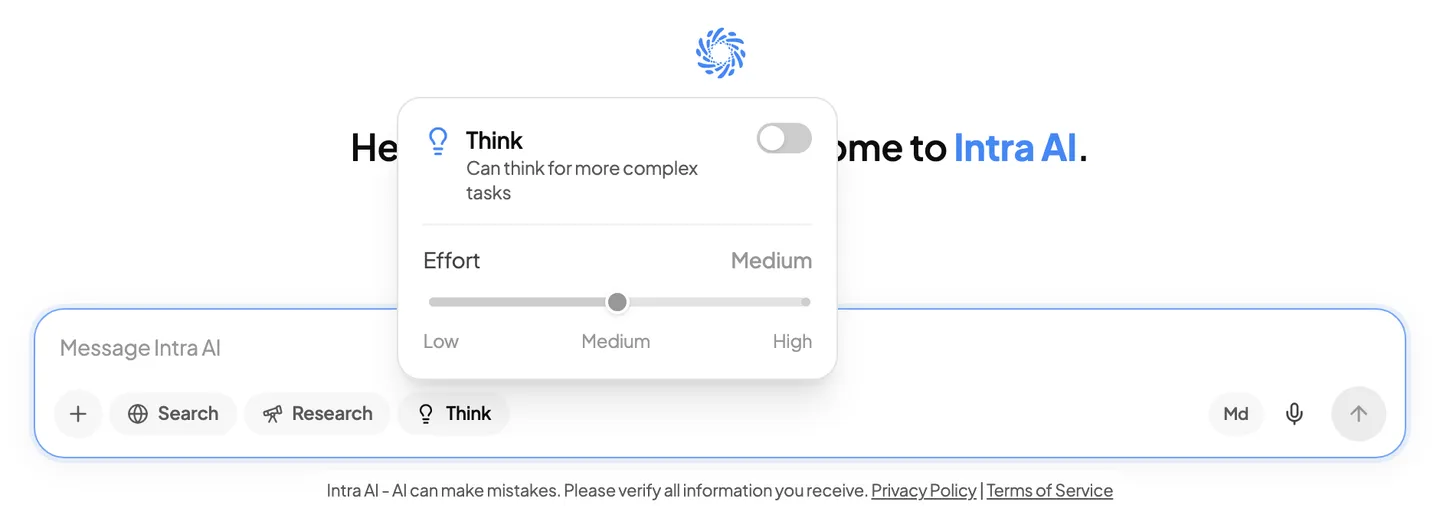 Das Denken-Popover mit dem Regler Niedrig / Mittel / Hoch
Das Denken-Popover mit dem Regler Niedrig / Mittel / Hoch
Was Sie im Popover sehen, hängt vom Modell ab:
| Modelltyp | Angezeigte Steuerelemente |
|---|---|
| Reasoning-fähiges Modell (z. B. Qwen3.6) | Ein Ein/Aus-Schalter und ein Niedrig / Mittel / Hoch-Aufwandsregler |
| Andere Modelle | Nur Ein/Aus-Schalter |
Aufwandsstufen (nur bei Reasoning-fähigen Modellen):
| Stufe | Bedeutung |
|---|---|
| Niedrig | Kurzer Denkdurchlauf – schnelle Antworten, gut für unkomplizierte Fragen |
| Mittel | Ausgewogene Tiefe (Standard bei eingeschaltetem Denken) |
| Hoch | Tiefes, methodisches Denken – langsamer, aber gründlicher; gut für komplexe Analysen, mehrstufige Probleme oder kniffeligen Code |
Wenn bei einer Antwort das Denken genutzt wurde, erscheint darüber ein aufklappbares Feld N Sekunden nachgedacht. Klicken Sie darauf, um nachzulesen, wie das Modell das Problem durchdacht hat.
Tipp: Höherer Aufwand lohnt sich bei mehrstufigen Problemen, sorgfältigen Analysen und schwierigen Code-Fragen. Für schnelle Suchen oder einfache Anfragen halten Niedrig oder Aus die Antworten schnell und verbrauchen weniger Token.
Ihre Denk-Einstellung wird für den aktuellen Browser-Tab gespeichert und zurückgesetzt, wenn Sie den Tab schließen.
Hinweis: Die Schaltfläche „Denken" erscheint nur, wenn das ausgewählte Modell Reasoning unterstützt. Wenn Sie sie nicht sehen, verfügt das aktuell ausgewählte Modell nicht über diese Funktion.
Websuche und Deep Research#
Zwei Pillen in der Composer-Leiste ermöglichen es dem Modell, über seine Trainingsdaten hinaus nach aktuellen Informationen zu suchen. Beide erfordern, dass Ihr Administrator die Websuche für Ihren Arbeitsbereich aktiviert hat.
 Das Eingabefeld mit den Schaltern Suche, Recherche und Denken sowie den Schaltflächen für Markdown und Mikrofon
Das Eingabefeld mit den Schaltern Suche, Recherche und Denken sowie den Schaltflächen für Markdown und Mikrofon
Die Pillen schließen sich gegenseitig aus – Sie können Suche oder Recherche für eine bestimmte Nachricht aktivieren, aber nicht beide gleichzeitig. Das Aktivieren der einen schaltet die andere automatisch aus.
| Pille | Symbol | Funktion |
|---|---|---|
| Suche | Globus | Stellt dem Modell für diese Nachricht aktuelle Web-Ergebnisse bereit. Quellkarten erscheinen unter der Antwort, und Inline-Zitatmarken [N] in der Antwort öffnen eine Vorschau der zitierten Seite beim Anklicken. |
| Recherche | Teleskop | Startet Deep Research – einen mehrstufigen Prozess, der Teilfragen plant, das Web durchsucht, Seiten liest, die Ergebnisse reflektiert und einen schriftlichen Bericht zusammenfasst. Ein Live-Fortschrittsbereich zeigt jede Phase während ihrer Ausführung an. Die Recherche läuft im Hintergrund weiter, auch wenn Sie die Seite verlassen. |
Tipp: Nutzen Sie Suche für eine schnelle, aktuelle Antwort mit zitierten Quellen. Nutzen Sie Recherche, wenn Sie einen gründlichen, quellenübergreifenden schriftlichen Bericht möchten und bereit sind, einige Minuten zu warten.
Hinweis: Beide Pillen sind ausgeblendet, wenn Ihr Administrator die Websuche nicht aktiviert hat. Wenn Sie sie nicht sehen, wenden Sie sich an Ihren Administrator.
Die vollständige Anleitung finden Sie auf der Seite Websuche.
Mit Dokumenten im Chat arbeiten#
Sie können die Antwort der KI auf Ihre eigenen Dateien stützen. Dies wird als Retrieval bezeichnet (manchmal auch als RAG abgekürzt): Die KI durchsucht die relevanten Passagen in Ihren Dokumenten und zitiert sie in ihrer Antwort, anstatt sich ausschließlich auf ihr Trainingswissen zu verlassen.
Dateien anhängen
Klicken Sie auf die Plus-Schaltfläche (Plus-Symbol links im Eingabefeld), um Dateien anzuhängen. Sie können:
- Eine vorhandene Datei aus Ihrer persönlichen Bibliothek oder Ihrem Projekt anhängen.
- Eine neue Datei direkt von Ihrem Gerät hochladen.
- Ein Bild einfügen in das Eingabefeld (wenn das ausgewählte Modell Bilder unterstützt).
An eine Nachricht angehängte Dateien werden automatisch zusammen mit allen Dateien in Ihrem aktiven Projekt und allen Dateien, die ein Agent mitbringt, durchsucht.
Hinweis: Datei-Uploads müssen von Ihrem Administrator aktiviert werden. Wenn die Plus-Schaltfläche nicht erscheint, wurde diese Funktion für Ihren Arbeitsbereich nicht aktiviert.
Die Quellenzeile
Nach einer Antwort, die auf Dateiinhalten basiert, erscheint unter dem Antworttext eine aufklappbare Zeile N Quellen. Klicken Sie darauf, um sie zu erweitern und zu sehen, welche Passagen verwendet wurden.
Jeder Quelleneintrag zeigt:
| Angabe | Bedeutung |
|---|---|
| Dateiname | Aus welchem Dokument die Passage stammt |
| Abschnittsüberschrift | Wo im Dokument sich die Passage befindet |
| Seitenzahl | Die Seite, auf der sich die Passage befindet |
| Relevanzwert | Wie genau die Passage zu Ihrer Frage passt |
| Textausschnitt | Ein kurzer Auszug des gefundenen Texts |
Klicken Sie auf einen Quelleneintrag, um eine vollständige Vorschau der Datei zu öffnen.
Wie Uploads, Textextraktion und Übersetzung funktionieren, erfahren Sie auf der Seite Dateien & Wissen.
Tool-Aufrufe und Agenten-Laufkarten#
Wenn das Modell (oder ein Agent) ein Tool verwendet, sehen Sie genau, was passiert ist.
- Ein einzelner Tool-Aufruf erscheint als kleine inline-Karte, die Sie erweitern können, um Eingabe und Ausgabe zu lesen.
- Zwei oder mehr Tool-Aufrufe in einem Zug werden hinter einer Zusammenfassungskarte N Tool-Aufrufe gruppiert. Sie öffnet sich automatisch, während der Lauf in Bearbeitung ist, und klappt sich nach Abschluss des Laufs von selbst wieder zusammen.
- Web-Suchergebnisse, Datei-Suchergebnisse und Code-Ausgaben erhalten jeweils eine eigene zweckmäßige Karte, damit sie auf einen Blick gut lesbar sind.
Wenn ein Agent Arbeit an einen Unter-Agenten delegiert, erscheint der Lauf dieses Unter-Agenten als eigene Karte mit dem Status je Schritt, der Anzahl der verwendeten Token und der benötigten Zeit.
Erweiterte Eingabefunktionen#
Das Eingabefeld kann mehr als nur reinen Text.
Zitieren und antworten
Markieren Sie beliebigen Text in einer Nachricht (Ihrer eigenen oder der KI) und eine Pille Intra AI fragen erscheint über der Auswahl. Klicken Sie darauf, um den Text als zitierten Auszug über dem Eingabefeld anzuheften. Wenn Sie Ihre nächste Nachricht senden, wird das Zitat automatisch als Kontext eingefügt. Das ist nützlich, wenn Sie eine Folgefrage zu einem bestimmten Satz oder einer Passage stellen möchten.
Sie können vor dem Senden mehrere Zitate hinzufügen. Jedes erscheint als Chip über dem Textbereich mit einer Entfernen-Schaltfläche (✕), um es zu verwerfen.
Markdown-Modus
Klicken Sie auf die Schaltfläche Md in der Composer-Leiste, um die Formatierungsleiste einzuschalten. Wenn der Markdown-Modus aktiv ist:
- Eine schmale Formatierungsleiste erscheint über dem Textbereich mit Schaltflächen für Fett, Kursiv, Inline-Code, Link, Aufzählungsliste, nummerierte Liste und Zitat.
- Ein Umschalter Bearbeiten / Vorschau ermöglicht es Ihnen, zwischen dem Schreiben und der formatierten Darstellung vor dem Senden zu wechseln.
- Tastaturkürzel funktionieren im Bearbeitungsmodus:
⌘BFett,⌘IKursiv,⌘EInline-Code,⌘KLink.⌘⇧Mschaltet den Markdown-Modus von überall im Composer ein/aus. - Klicken Sie auf die Schaltfläche ⋮ in der Leiste, um anzupassen, welche der 12 verfügbaren Formatierungsschaltflächen angezeigt werden.
Ihre Markdown-Einstellung wird in Ihrem Profil gespeichert und bleibt zwischen Sitzungen erhalten.
Gespeicherte Prompts (Slash-Befehl)
Geben Sie / am Anfang eines leeren Eingabefelds ein, um die Auswahl für gespeicherte Prompts zu öffnen.
Eine schwebende Liste erscheint mit:
| Bereichs-Pille | Was angezeigt wird |
|---|---|
| GLOBAL (lila) | Prompts, die Ihr Administrator mit allen geteilt hat |
| PERSÖNLICH (grau) | Prompts, die Sie selbst erstellt haben |
Tippen Sie nach dem / weiter, um nach Titel oder Inhalt zu filtern. Verwenden Sie die Pfeiltasten zur Navigation und Enter zum Einfügen, oder klicken Sie auf eine beliebige Zeile. Der vollständige Prompt-Text ersetzt den Inhalt des Eingabefelds.
Sie können Ihre persönlichen Prompts unter Einstellungen → Prompts erstellen und verwalten. Administratoren verwalten globale Prompts im Admin-Bereich.
Temporärer Chat (Inkognito)#
Ein temporärer Chat ist eine Sitzung, die niemals auf dem Server gespeichert wird. Nutzen Sie ihn, wenn Sie etwas fragen möchten, das nicht in Ihrem Konversationsverlauf gespeichert werden soll.
Um einen zu starten: Klicken Sie auf Ihren Namen oder Avatar am unteren Ende der Seitenleiste, um das Kontomenü zu öffnen, und wählen Sie dann die Option für temporären Chat.
In einem temporären Chat:
- Über dem Eingabefeld erscheint eine Kennzeichnung Temporärer Chat mit einem Geist-Symbol.
- Das Eingabefeld selbst hat einen gestrichelten Rahmen, sodass der Modus jederzeit sichtbar ist.
- Ein Hinweis unter dem Feld bestätigt: Temporäre Chats werden nicht gespeichert.
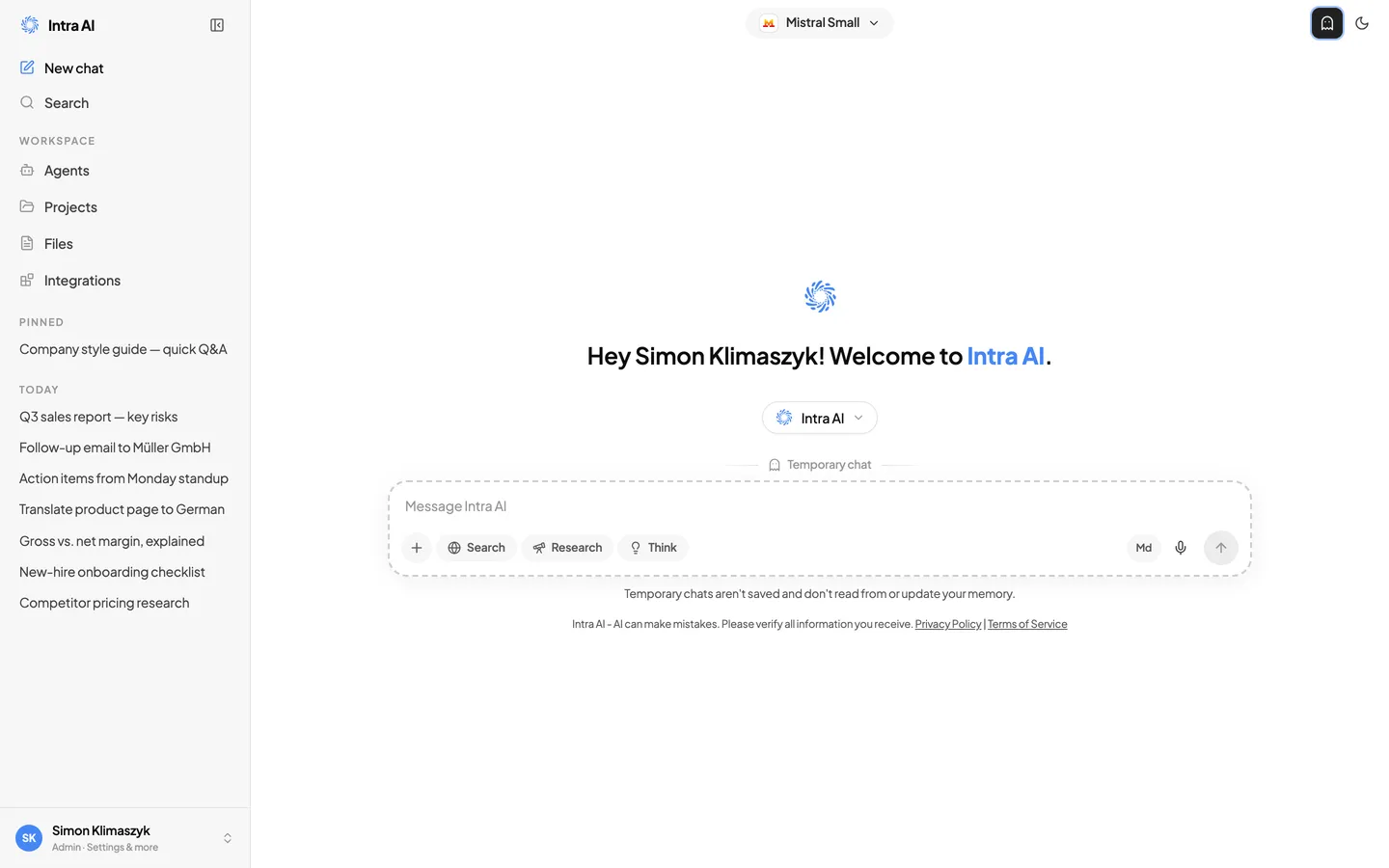 Das Eingabefeld im temporären Chat mit gestricheltem Rahmen und der Kennzeichnung „Temporärer Chat"
Das Eingabefeld im temporären Chat mit gestricheltem Rahmen und der Kennzeichnung „Temporärer Chat"
Während Sie sich in einem temporären Chat befinden:
- Die Konversation wird vom Server gelöscht, sobald Sie die Seite verlassen oder den Tab schließen.
- Sie kann weder geteilt noch exportiert werden und ist nicht wieder abrufbar.
- Ihr Gedächtnis wird weder gelesen noch beschrieben – die KI verwendet keine über Sie gespeicherten Fakten, und aus der Sitzung wird nichts gespeichert.
Warnung: Es gibt keine Möglichkeit, einen temporären Chat nach dem Verlassen wiederherzustellen. Wenn Sie einen Teil der Konversation behalten möchten, kopieren Sie ihn heraus, bevor Sie die Seite verlassen.
Konversation anzeigen und lesen#
Wie Nachrichten angezeigt werden
Ihre Nachrichten erscheinen auf der rechten Seite; die Antworten der KI erscheinen auf der linken Seite. Antworten werden als formatierter Text dargestellt – die KI kann Überschriften, Aufzählungslisten, Code-Blöcke mit Syntaxhervorhebung, Tabellen und mathematische Ausdrücke erzeugen.
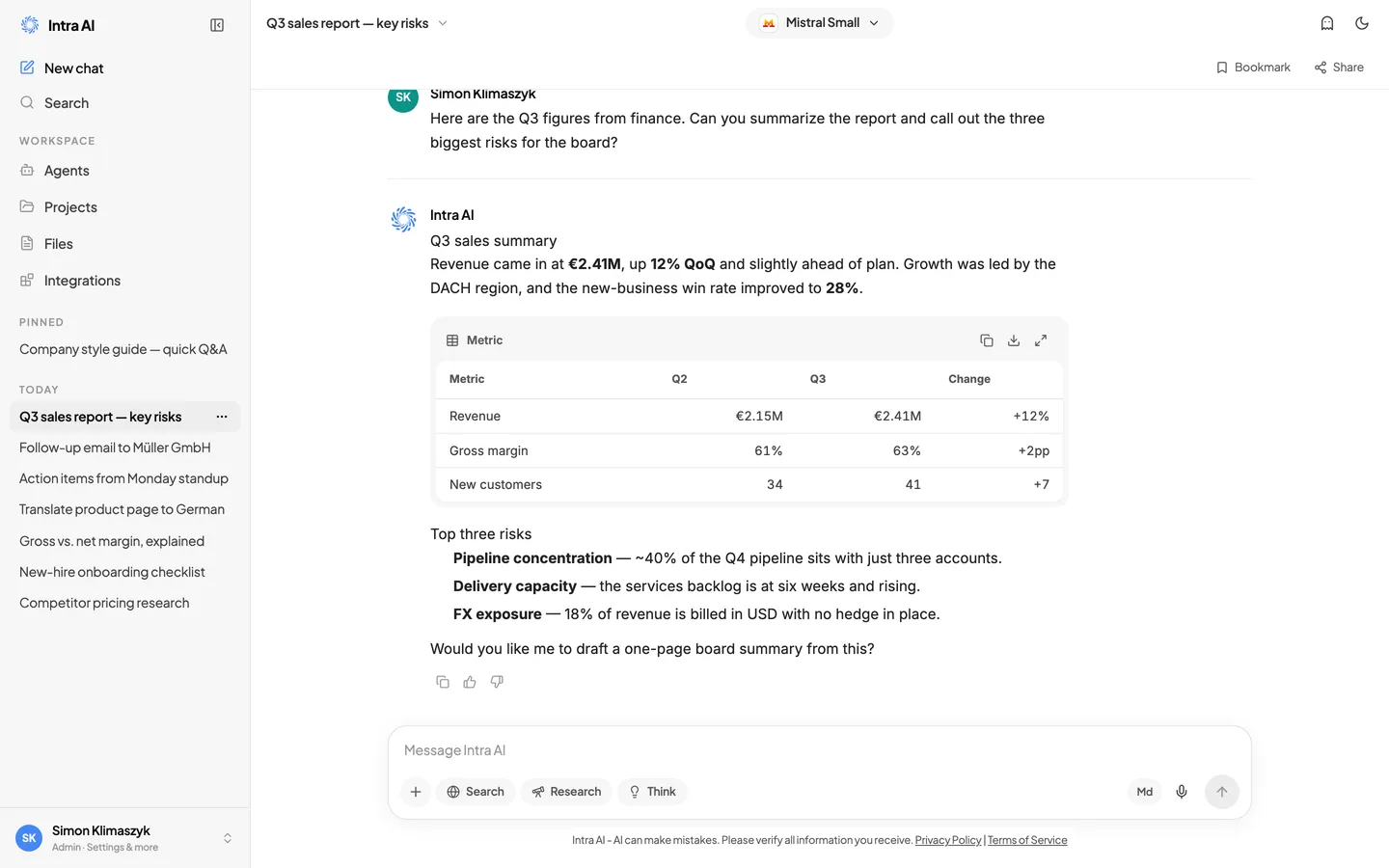 Eine Konversation mit formatierten Markdown-Antworten und einem Code-Block
Eine Konversation mit formatierten Markdown-Antworten und einem Code-Block
Code-Blöcke haben eine Schaltfläche Kopieren in der oberen rechten Ecke, damit Sie den Code mit einem Klick übernehmen können.
Ältere Nachrichten werden beim Scrollen nachgeladen
Lange Konversationen werden nicht alle auf einmal geladen. Wenn Sie nach oben scrollen, werden ältere Nachrichten automatisch nachgeladen. Das hält die Seite auch bei sehr langen Threads schnell.
Nach unten springen
Wenn Sie nach oben scrollen, während eine Antwort gestreamt wird, erscheint am unteren Bildschirmrand eine Nach-unten-springen-Pille. Klicken Sie darauf, um zur neuesten Nachricht zu springen. Die Pille verschwindet automatisch, sobald die Antwort abgeschlossen ist und Sie zur unteren Position zurückgekehrt sind.
Token-Verbrauch
Die Anzahl der von jeder abgeschlossenen Antwort verwendeten Token wird darunter in kleiner Schrift angezeigt. Token sind die Einheit, die die KI zur Messung der Textlänge verwendet – grob gesagt entspricht ein Token etwa drei Vierteln eines deutschen Worts. Das Beobachten dieser Zahl hilft Ihnen, den Verbrauch Ihres Arbeitsbereichs-Guthabens im Blick zu behalten.
Gespeicherte-Erinnerungen-Bereich
Wenn die KI während einer Konversation etwas in Ihrem Langzeitgedächtnis speichert, erscheint unter der Antwort ein aufklappbares blaues Feld. Es listet jeden gespeicherten Fakt mit Schlüssel und Wert auf.
- Klicken Sie auf die Kopfzeile des Felds, um die Liste zu erweitern oder zu reduzieren. Es öffnet sich automatisch beim ersten Speichern einer Erinnerung, damit Sie stets bemerken, wenn etwas aufgezeichnet wird.
- Klicken Sie neben einem Eintrag auf Vergessen (mit einem Papierkorb-Symbol), um diesen Fakt sofort zu löschen.
Konversation verwalten#
Umbenennen, Archivieren und Löschen
Klicken Sie auf den Konversationstitel oben auf dem Bildschirm (er hat ein kleines Chevron), um auf die Konversationsaktionen zuzugreifen.
| Sie sind… | Verfügbare Aktionen |
|---|---|
| Eigentümer | Umbenennen, Archivieren, Löschen |
| Nicht Eigentümer (geteilter Chat) | Verlassen |
- Umbenennen ersetzt den Titel durch ein inline-Textfeld – tippen Sie und drücken Sie
Enter(oder klicken Sie irgendwo anders hin), um zu speichern. - Archivieren entfernt die Konversation aus der Hauptliste und verschiebt sie in den Bereich „Archiviert" in der Seitenleiste. Archivierte Konversationen sind weiterhin durchsuchbar und können wiederhergestellt werden.
- Löschen entfernt die Konversation nach einer Bestätigungsaufforderung dauerhaft. Dies kann nicht rückgängig gemacht werden.
- Verlassen (nur geteilte Chats) entfernt Sie aus der Konversation. Sie werden sie nicht mehr in Ihrer Seitenleiste sehen.
Konversation anpinnen
Fahren Sie in der Seitenleiste über eine beliebige Konversationszeile und öffnen Sie das ⋯-Menü, um sie Anpinnen. Angeheftete Konversationen erscheinen in einer dedizierten Gruppe Angeheftet am oberen Ende der Seitenleistenliste, oberhalb der zeitlich gruppierten Konversationen.
Hinweis: Ihr Administrator entscheidet, welche Modelle, Websuche, Datei-Uploads und andere Funktionen Ihnen zur Verfügung stehen. Wenn etwas hier Beschriebenes nicht sichtbar ist, ist es für Ihren Arbeitsbereich möglicherweise nicht aktiviert.
Fehlerbehebung / Warum kann ich X nicht sehen?#
| Symptom | Wahrscheinliche Ursache | Was zu tun ist |
|---|---|---|
| Die Pille Suche oder Recherche ist nicht sichtbar | Die Websuche wurde von Ihrem Administrator nicht aktiviert | Bitten Sie Ihren Administrator, sie in der Systemkonfiguration zu aktivieren |
| Die Schaltfläche Denken (Glühbirne) ist nicht sichtbar | Das ausgewählte Modell unterstützt kein Reasoning | Wechseln Sie zu einem Reasoning-fähigen Modell wie Qwen3.6 |
| Die Schaltfläche Plus (Datei anhängen) ist nicht sichtbar | Uploads wurden nicht aktiviert | Bitten Sie Ihren Administrator, die Upload-Funktion zu aktivieren |
| Die Schaltfläche Mikrofon ist nicht sichtbar | Spracheingabe wurde nicht aktiviert, oder Ihr Browser unterstützt sie nicht | Wenden Sie sich an Ihren Administrator, oder versuchen Sie es mit einem unterstützten Browser |
| Eine Antwort zeigt abgeschnittenen Text | Sie haben auf Stoppen geklickt, oder die Generierung wurde unterbrochen | Klicken Sie auf Wiederholen, um eine vollständige Antwort zu erhalten |
| Die Antwort zeigt eine Fehlerkarte anstelle von Text | Beim KI-Anbieter gab es ein vorübergehendes Problem | Warten Sie einen Moment und klicken Sie auf Wiederholen; wenn das Problem anhält, wenden Sie sich an Ihren Administrator |
| Ein Modell, das ich zuvor verwendet habe, ist nicht mehr in der Liste | Ihr Administrator hat es entfernt oder deaktiviert | Fragen Sie Ihren Administrator, welche Modelle verfügbar sind |
| Die Konversation ist aus meiner Seitenleiste verschwunden | Sie wurde möglicherweise archiviert oder gelöscht | Überprüfen Sie den Bereich Archiviert am unteren Ende der Seitenleiste |
Häufig gestellte Fragen#
F: Erinnert sich das Modell an das, was ich in einer vorherigen Konversation gesagt habe? A: Nicht automatisch. Jede Konversation ist eigenständig. Wenn jedoch die Gedächtnisfunktion aktiviert ist und die KI Fakten aus einer früheren Sitzung extrahiert hat, können diese Fakten in zukünftigen Konversationen zur Personalisierung von Antworten verwendet werden. Um zu sehen, was gespeichert ist, besuchen Sie Gedächtnis.
F: Kann ich in jeder Konversation dasselbe Modell verwenden? A: Ja. Ihre Modellauswahl bleibt für die aktuelle Browser-Sitzung über Konversationen hinweg erhalten. Sie wird nur auf das Standardmodell des Arbeitsbereichs zurückgesetzt, wenn Sie die Seite neu laden oder sich erneut anmelden.
F: Warum dauert meine Antwort so lange? A: Mehrere Dinge können eine Antwort verlangsamen: Das Modell ist ausgelastet (besonders häufig zu Stoßzeiten), Denken ist auf hohen Aufwand eingestellt, oder Deep Research läuft gerade. Sie können jederzeit auf Stoppen klicken und anschließend auf Wiederholen, wenn Sie eine schnellere Antwort mit niedrigeren Einstellungen möchten.
F: Kann ich eine Konversation beginnen und auf einem anderen Gerät fortsetzen? A: Ja. Konversationen werden auf dem Server gespeichert (es sei denn, Sie befinden sich in einem temporären Chat). Melden Sie sich auf einem beliebigen Gerät an, und die Konversation erscheint in Ihrer Seitenleiste.
F: Was passiert mit meinen Dateien, nachdem ich sie angehängt habe? A: Von Ihnen hochgeladene Dateien werden in Ihrer persönlichen Dateibibliothek gespeichert und stehen für zukünftige Konversationen zur Verfügung. Weitere Informationen zur Verwaltung, zum Löschen oder zum Teilen Ihrer Dateien finden Sie unter Dateien & Wissen.
F: Können andere Personen meine Konversationen sehen? A: Standardmäßig nicht. Konversationen sind privat für Sie. Sie können eine Konversation explizit über die Schaltfläche „Teilen" freigeben, wenn die Chat-Freigabe von Ihrem Administrator aktiviert wurde. Weitere Details finden Sie unter Chat-Freigabe.
F: Die KI hat mir eine falsche Antwort gegeben. Was soll ich tun? A: Klicken Sie auf Wiederholen, um eine neue Antwort zu erhalten. Wenn die Antwort dauerhaft falsch ist, versuchen Sie, Ihre Nachricht zu bearbeiten und präziser zu formulieren, oder aktivieren Sie die Pille Suche, um dem Modell Zugriff auf aktuelle Quellen zu geben.
Verwandt: Agenten · Dateien & Wissen · Gedächtnis · Websuche · Suche & Lesezeichen · Chat-Freigabe